Incrementalized queries in adhesive categories
Kris Brown

(press s for speaker notes)
5/1/25
Overview
$$
$$
In a very generic setting, we can formulate an incremental search problem and its solution.
General, but concrete enough that we obtain an algorithm which can be efficiently instantiated in a wide variety of settings.
The examples queries being incrementalized are conjunctive queries of relational databases
In particular: directed multigraphs where schema is \(\boxed{Edge \overset{s}{\underset{t}{\rightrightarrows}} Vertex}\)
The problem we address is one where changes are induced by rewrite rules. We want to leverage our knowledge of which rule which induced the change to more efficiently update queries with respect to the change.

Applications: e-graphs, compiler optimizations, database chase, agent-based model simulations
Dictionary for category theory concepts
| Informal term | Categorical analogue |
|---|---|
| Setting for incremental search problem | An (adhesive) category \(\mathsf{C}\) |
| Pattern / Query | An object, \(X \in \operatorname{Ob}\mathsf{C}\) |
| State of the world / set of facts | An object \(G \in \operatorname{Ob}\mathsf{C}\) |
| Pattern match of \(X\) in \(G\) | A morphism \(X \rightarrow G\) |
| Answer set to a query \(X\) in state \(G\) | \(\operatorname{Hom}_\mathsf{C}(X,G)\) |
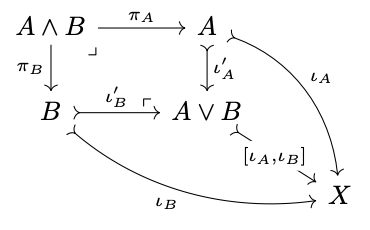
| An (additive) rewrite rule, with pattern \(L\) and replacement \(R\) | A monomorphism \(f: L \rightarrowtail R\) |
| Application of a rewrite rule \(f\) to state \(G\) with \(L\) matched via \(m\) | A pushout of \(f\) and \(m\) |
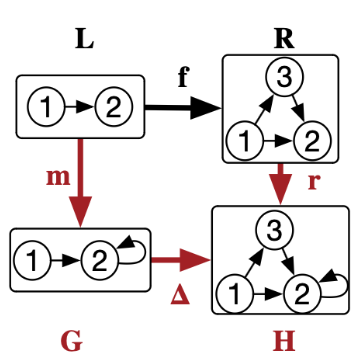
Incremental search problem: given \((G, H, m, \Delta, r)\), compute \(\operatorname{Hom}(X,H)\setminus \operatorname{Hom}(X,G)\cdot\Delta\)
Use only operations that scale with small objects (\(X,L,R\))
Another example
\[\textbf{Schema}\] 
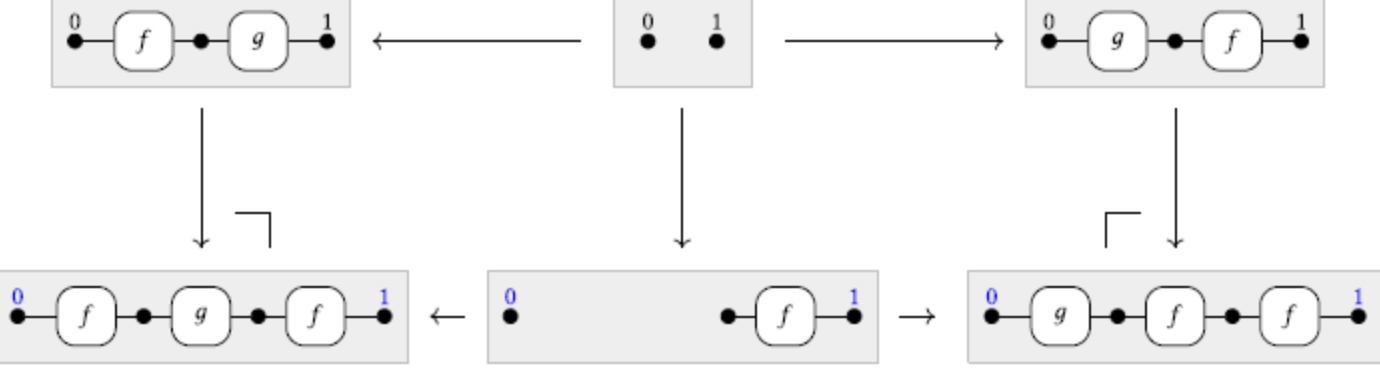
E.g. a rule which matches pairs \((A\times C)+(B\times C)\) and \((A+B)\times C\) and merges their e-classes.

Computational considerations
Objects in patterns and rules (\(L, R, X\)) are small.
The states being updated by rewrite rules (\(G, H\)) are large.
It’s computationally difficult to compute the answer set to a query \(\operatorname{Hom}(A,B)\) when \(B\) is large even when \(A\) is small (subgraph isomorphism problem); however, it’s easy to solve the rooted subgraph isomorphism problem so long as \(A\) is small.
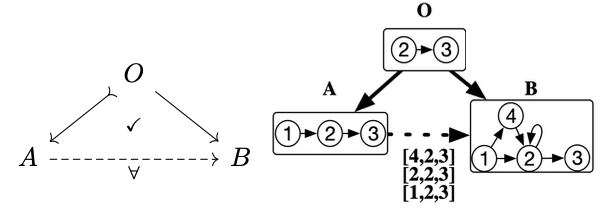
Such a partial map specifies a rooted homomorphism search problem when the monic map is componentwise connected, i.e. there exists no connected component of \(A\) which lies entirely outside the image of \(O\).
Working backwards towards a solution
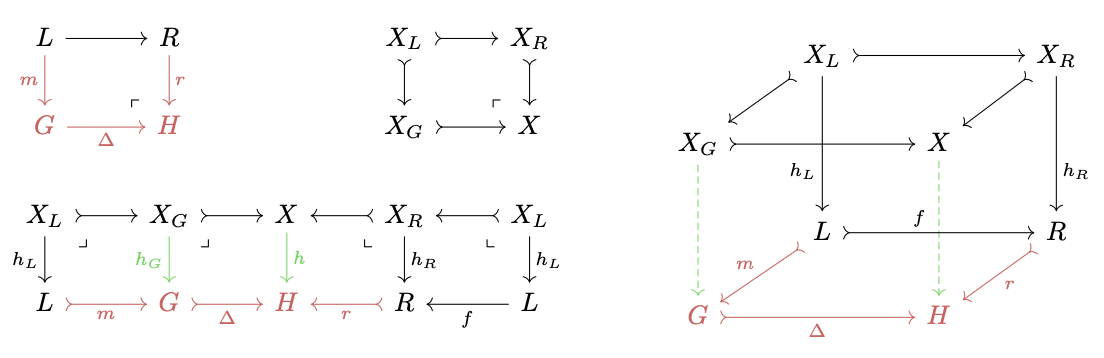
For any newly introduced match into the result of a rewrite, we have a canonical decomposition of our pattern into various subobjects.
This is a cube where the top and bottom are pushouts and the sides are all pullbacks.1
How much of this cube can be compute at compile time?
Example subobjects of a pattern

Top face of any cube will involve the choice of three of these elements.
The simple algorithm
At compile time
- Enumerate all possible top faces (decompositions \(X = X_G +_{X_L} X_R\))
- Enumerate all possible side faces above the rewrite rule:
- For each \(X_L\rightarrowtail X_R\) and each rewrite rule \(f\), enumerate all possible maps \(h_L: X_L\rightarrow L\) and \(h_R: X_R\rightarrow R\) such that a pullback square is formed.
One of these decompositions is bad: it has \(X_G=X\): this is saying the match lies entirely in \(G\).
At runtime: for each partial cube
Given \(m\) and \(\Delta\), we can compute all possible \(h_G: X_G\rightarrow G\) over the match via a rooted search problem, only keeping the ones which form a pullback square.
Then, \(h=[h_G\cdot \Delta, h_R\cdot r]\).
Example: finding newly introduced paths of length 2
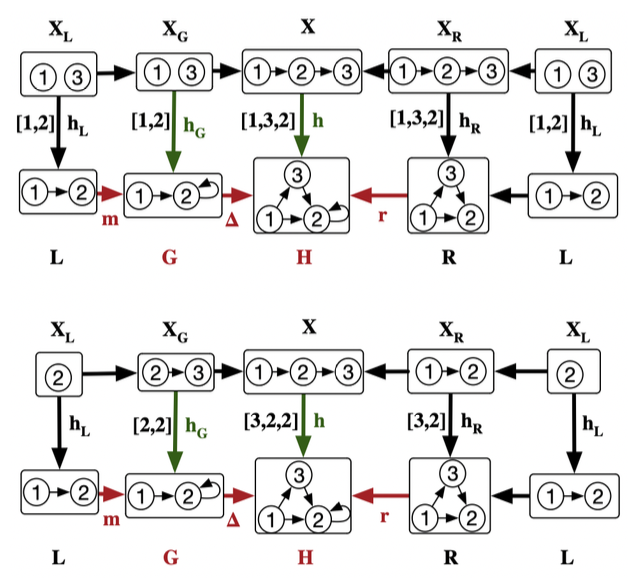
Is it faster than seminaive?
Prefactors! This is WIP, datalog experiments are TBD.

An optimization when \(\mathsf{C}\) has complements
We can be faster in two ways: 1. there are a lot of ways to express \(X\) as a pushout that we have to iterate over. 2. it might seem wasteful that we had to filter \(h_G\) candidates by those which formed a pullback square.
Optimized algorithm: we’ll also solve the problem if we use the same algorithm
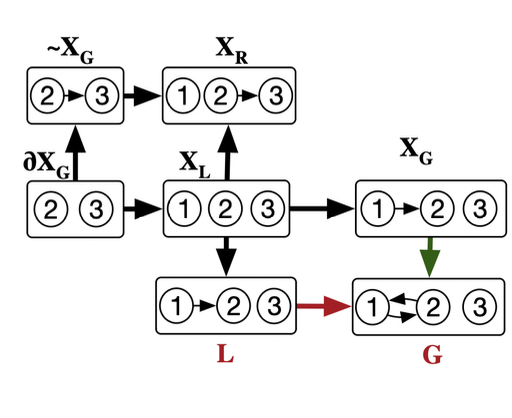
- Only consider decompositions where \(X_R = {\sim}X_G\).
- Keep all of the the extensions of the partial map \(h_G: X_G \leftarrowtail X_L \rightarrow G\).
Why is the optimization correct?
For any match \(h: X\rightarrow H\), we have not only a unique adhesive cube, but also what a unique minimal adhesive cube which one gets from composing two cubes together like in the below diagram:
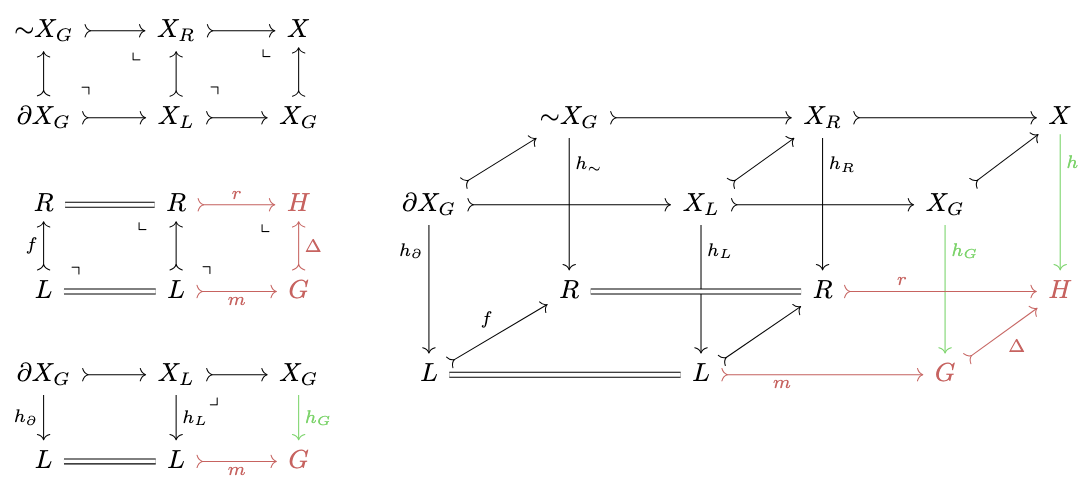
Note we can see this arbitrary \(h\) has a unique associated interaction between \(\partial X_G \rightarrowtail {\sim}X_G\) and \(f\), i.e. a pair of maps \((h_\partial, h_\sim)\) that forms a pullback with \(f\). We get this by precomposing \(h_l\) and \(h_r\) with \(\partial X_G \rightarrowtail X_L\) and \({\sim}X_G \rightarrowtail X_R\) respectively.
Iterating over minimal adhesive cubes is much nicer than iterating over adhesive cubes.
Optimized algorithm example
Batch update from multiple rule firings
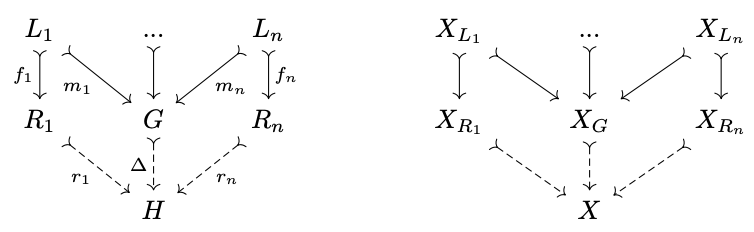
A match into the result of multiple simultaneous rewrites has a corresponding decomposition of the pattern into a colimit of subobjects of the same shape.
Our algorithm generalizes: at compile time enumerate possible decompositions of the above shape and all interactions with rewrite rules. At runtime, loop over possible partial ‘multicubes’ and look for morphisms \(h_G: X_G\rightarrow G\) that lead to pullback faces above all of the matches, which uniquely result in new matches \(h=[h_G\cdot \Delta, h_{r,1}\cdot r_1, ...]\).
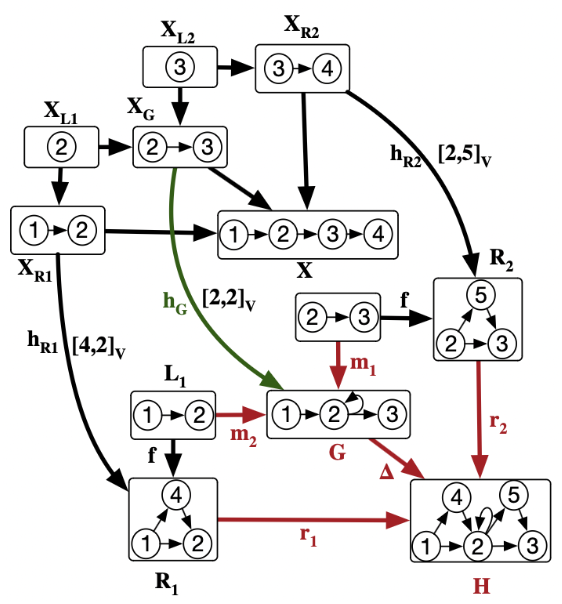
\[n=2\] 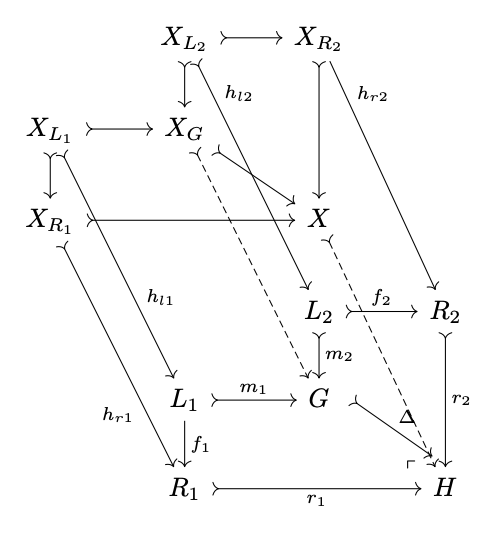
Batch example
Nonmonic matches
Nonmonic matches can implicitly quotient parts of the pattern, leading to new possible ways a match for a pattern \(X\) could be created. For every possible \(L\twoheadrightarrow L'\), we can compute the corresponding quotiented rule at compile time. At runtime, we epi-mono factorize any nonmonic match and use the previous algorithm with the quotiented rule.
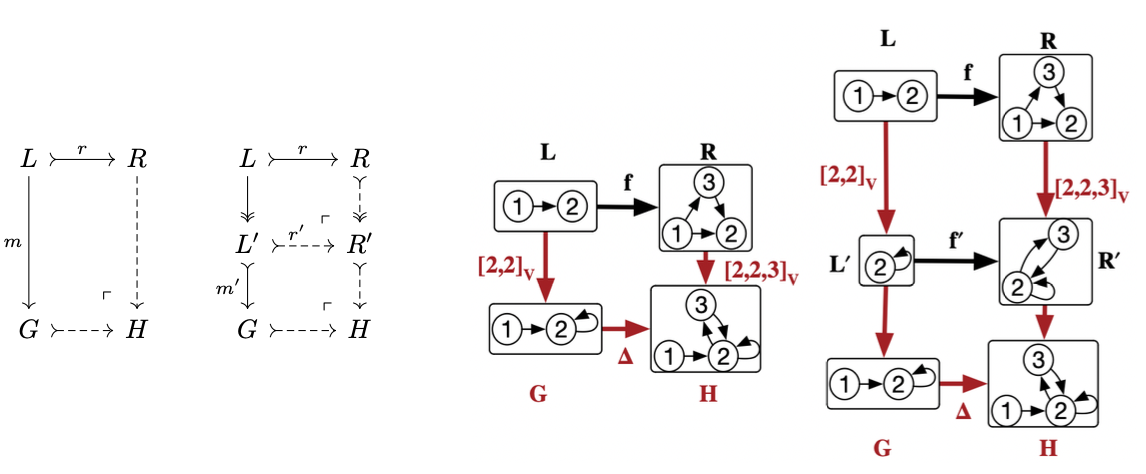
Merging
Everything said so far goes through when \(f\) is not monic.
- Adhesive categories still guarantee the existence of the adhesive cube.

However:
- It becomes more complicated in practice to enumerate possible top faces.
- The condition for a decomposition to be “trivial” is less simple to state.
- The condition for the optimization with complements is less simple to state.
Deletion
We can also use rewrite rules to delete (via a pushout complement).
Can state abstractly when a match has been deleted: pullback along the deletion is an iso.
However, many applications do not require deletion (e.g. the chase, e-graphs). Also many data structures can implement a form of “mark as deleted” that makes it trivial to check whether a match has been invalidated: lazily check any particular match to see if it refers to something marked as deleted.