Scientific and software engineering examples of applied category theory
Kris Brown - Topos Seminar

(press s for speaker notes)
6/5/23
Abstraction
$$
$$
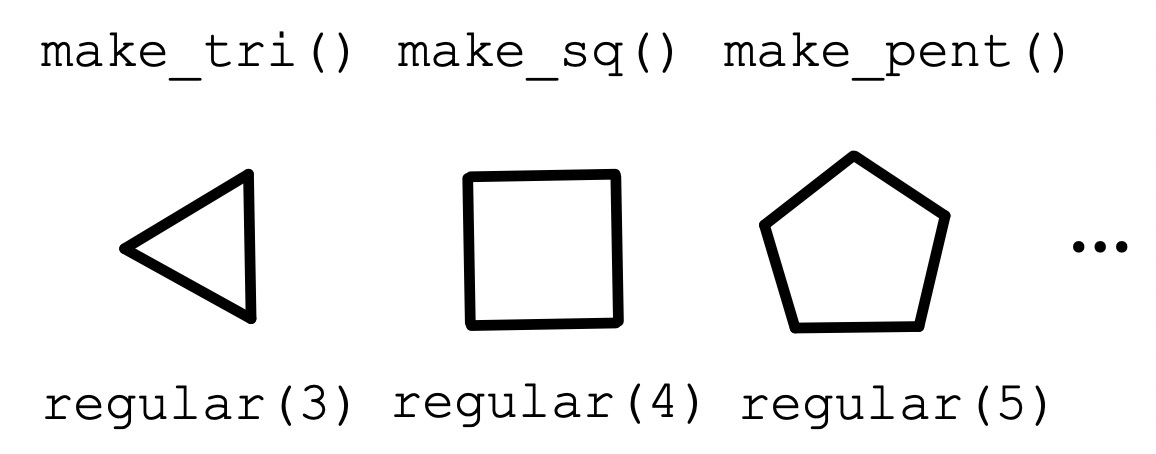

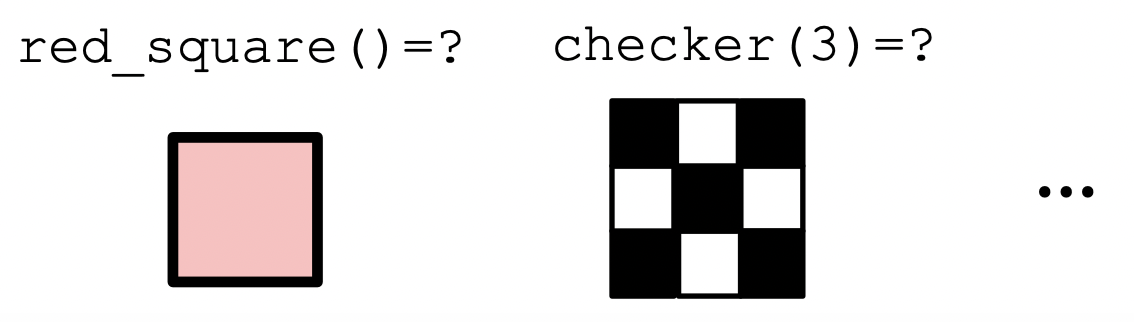
The status quo
Abstraction is something all programmers are familiar with.
- There are pros and cons to it. Cons follow when abstractions are ad hoc.
- E.g. they don’t fit well together, difficult to modify, unintelligible to peers
Category theory offers abstractions that fit well together.
- Scientific workflow can be improved to be conceptual, not manual, programming.
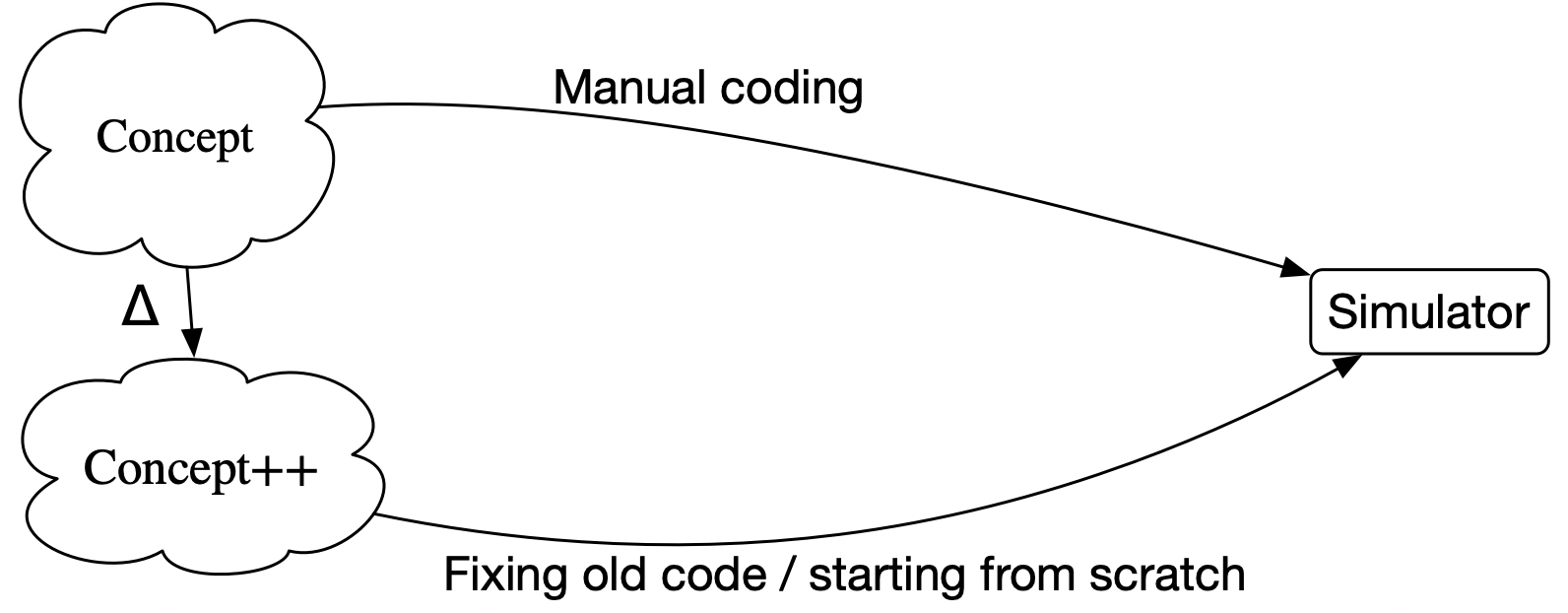
A better quo
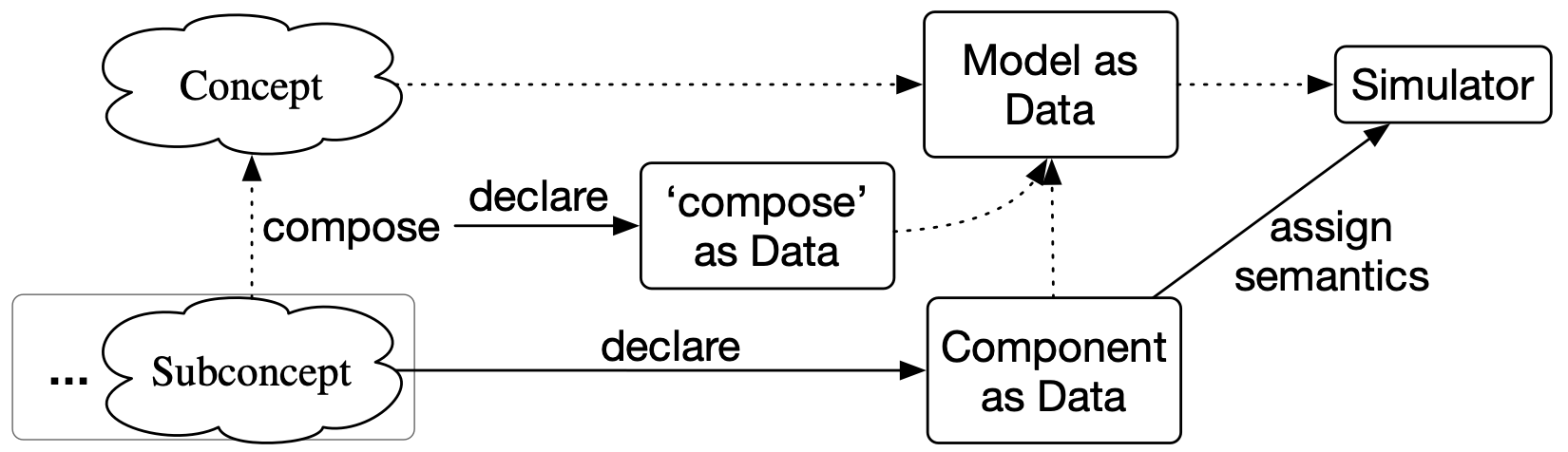
⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅
Why Category Theory?
Focuses on relationships between things without talking about the things themselves.
Invented in the 1940’s to connect different branches of math.
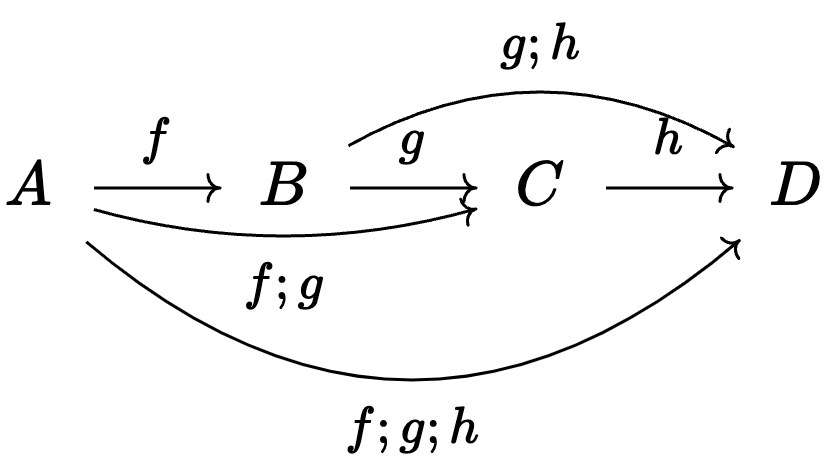
CT studies certain shapes of combinations of arrows.
- These can be local shapes, e.g. a span: \(\huge \cdot \leftarrow \cdot \rightarrow \cdot\)
- These can be global, e.g. an initial object: \(\huge \boxed{\cdot \rightarrow \cdot\rightarrow \cdot \rightarrow \dots}\)
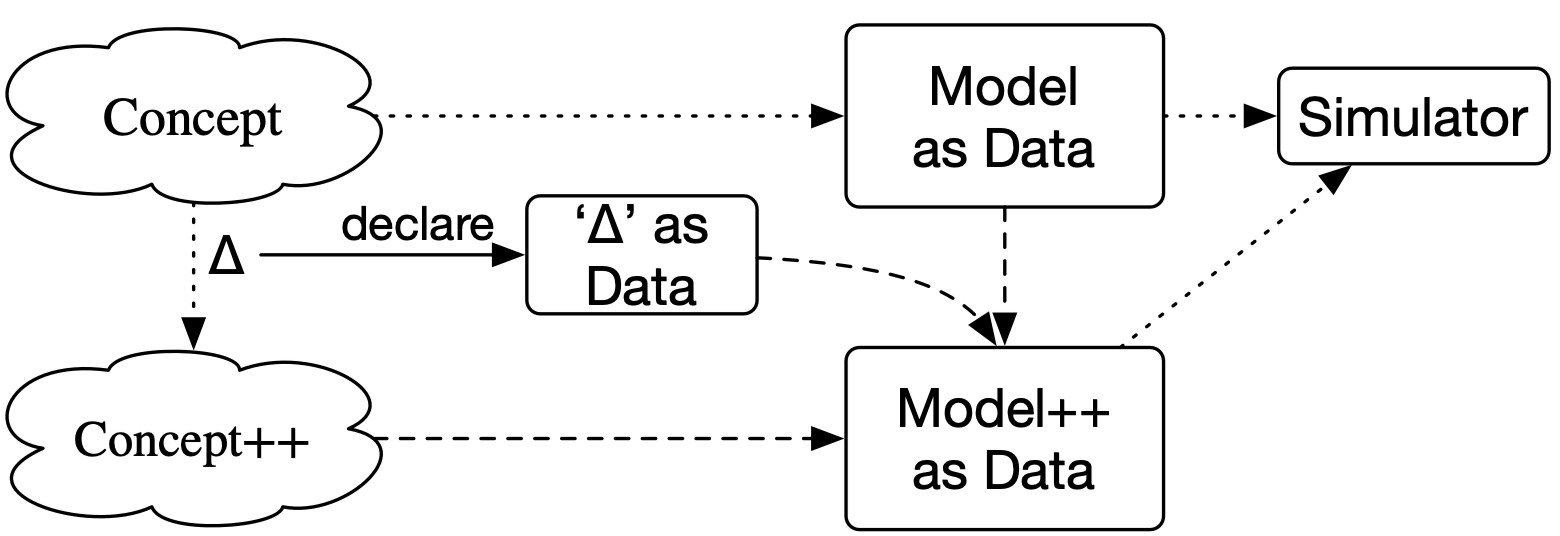
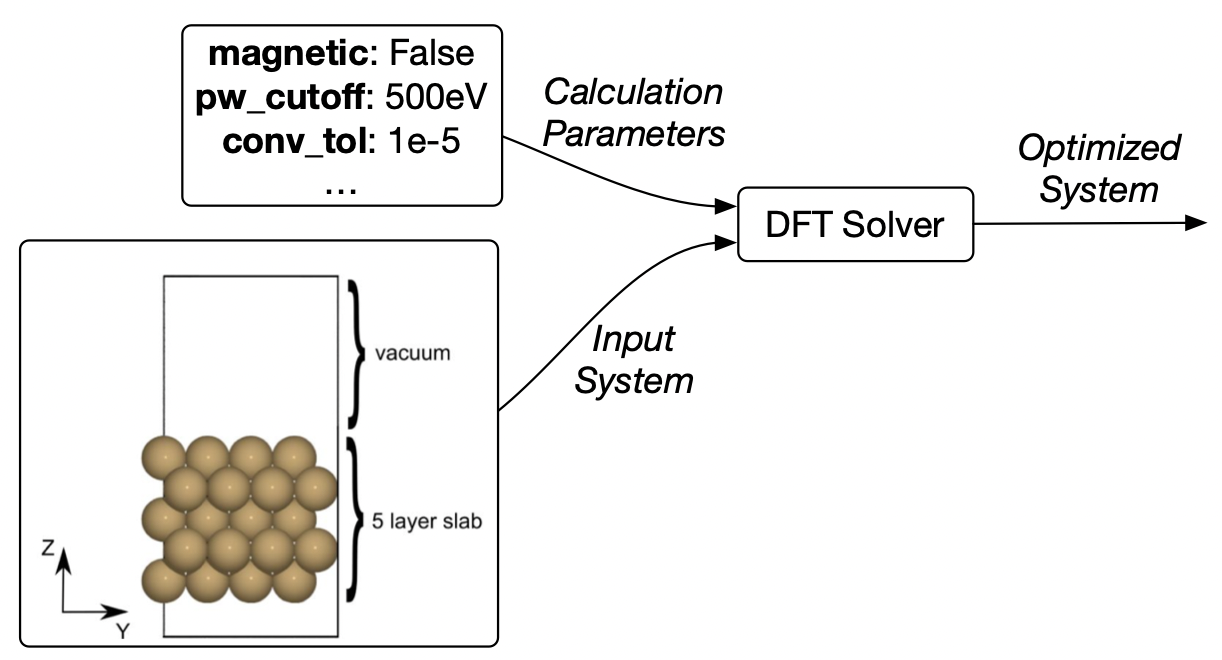
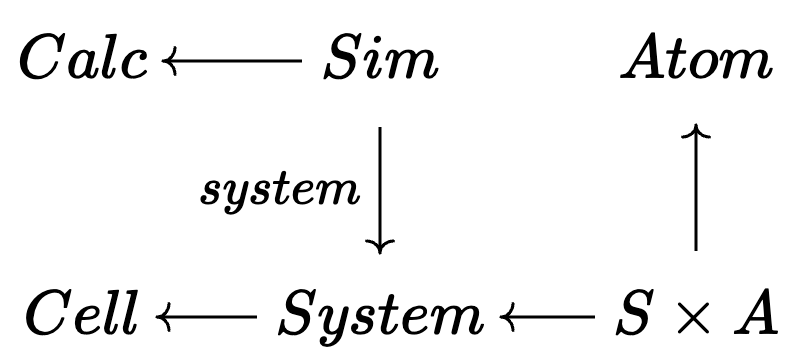
🗄️. DFT simulations
A simulation has the following data
🗄️. An improvement: databases
Example instance
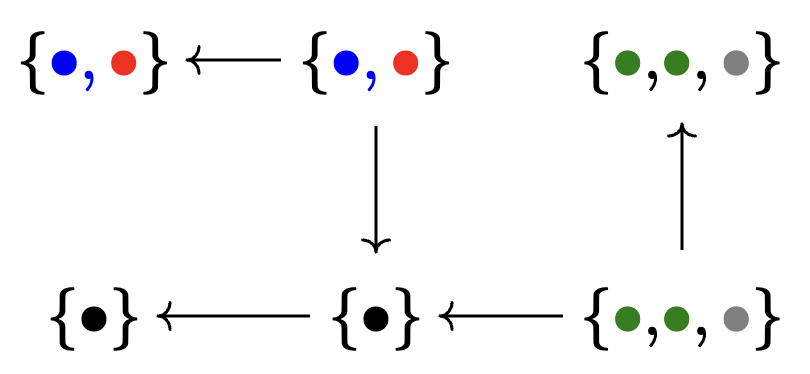
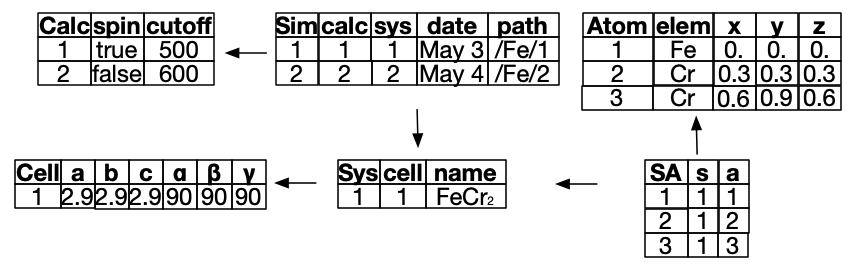
🗄️. Another improvement: C-Sets / ACSets
A \(\mathsf{C}\)-set has the same information as a database without attributes.
Attributed \(\mathsf{C}\)-sets (ACSets) have the same information as ordinary relational databases.
Unlike databases, we understand ACSets as living in a category which supplies many interesting and useful things to do with database that we would otherwise not think to do.
The majority of this talk will emphasize the sorts of things one can do with this perspective.
Example ACSet
🗄️. Head-to-head comparison



# File System
simulations/
|-bulk/
| |-magnetic/
| | |- Fe/
| | | |-pw_500/
| | | |-pw_600/
| | |- ...
| |-nonmagnetic/
| | |- Al/
| | | |-pw_500/
| | | |-pw_700/
| | |- ...
|-surface/
| |-magnetic/
| |- Au/
| | |-pw_500/
| |...# Python
class Atom():
def __init__(self, elem,x,y,z):
def __eq__(self, other):
class Cell():
def __init__(self, dims, pbc):
def __eq__(self, other):
class System():
def __init__(self, cell, atoms):
def __eq__(self, other):
class Calculator():
def __init__(self, params):
def __eq__(self, other):
class Sim():
def __init__(self, calc, sys):
def __eq__(self, other):
def write_input(self, pth: str):
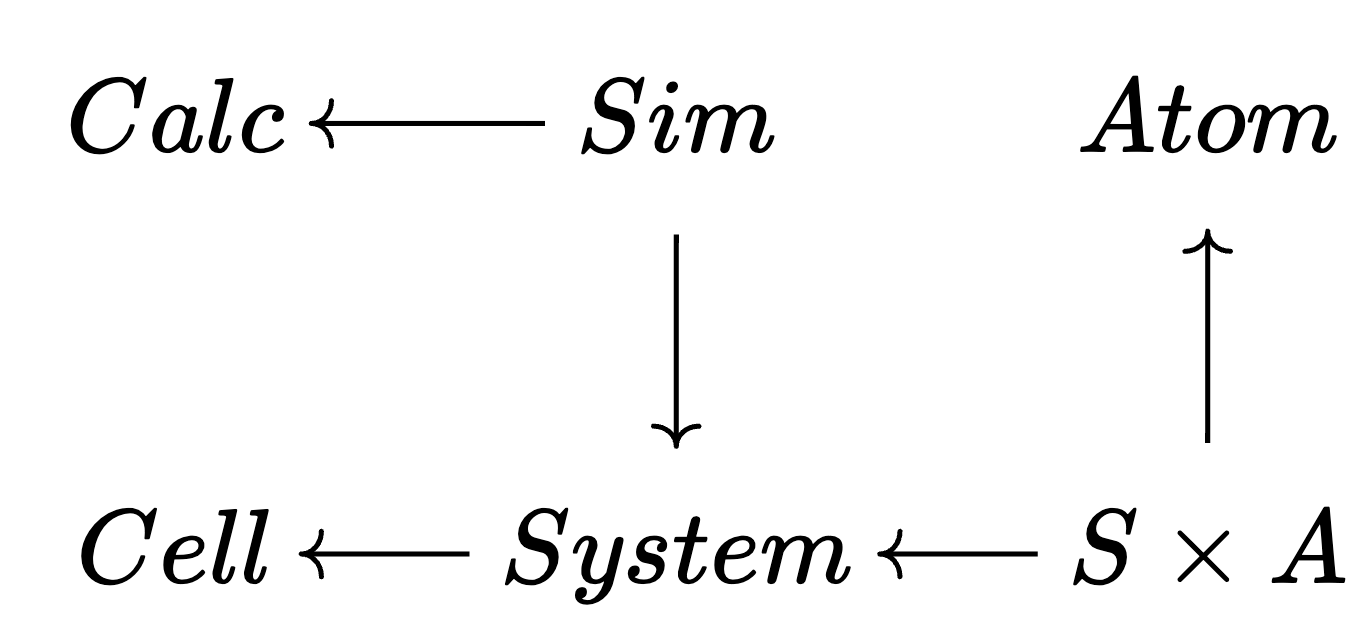
def read_input(pth: str) -> Sim:# AlgebraicJulia
@present Simulations begin
(Atom,S_A,Cell,System,Sim,Calc) :: Ob
(String, Float, Int) :: AttrType
calc :: Hom(Sim, Calc)
system :: Hom(Sim, System)
cell :: Hom(System, Cell)
s_system :: Hom(S_A, System)
s_atom :: Hom(S_A, Atom)
pw :: Attr(Calc, Float)
xc :: Attr(Calc, String)
(x,y,z) :: Attr(Atom, Float)
elem :: Attr(Atom, Int)
endFind pairs of simulations with the same calculator and cell but different atomic configurations.
# Python
CHEM_LEVEL = 3
"""Put paths into buckets. Same bucket if
their path (*ignoring* the 3rd folder name,
i.e. chemical structure) is the same."""
def find_pairs(sim_path_root):
EQcalc = defaultdict(list)
for p in get_all_paths(sim_path_root)
# e.g. p=["bulk","mag","Fe","pw_500",...]
# pth_no_chem=["bulk","mag","pw_500",...]
pth_no_chem = p[:CHEM_LEVEL]+p[CHEM_LEVEL+1:]
bucket = (get_calc(p), pth_no_chem)
EQcalc[bucket].append(p)
end
return EqCalcCell.values()🗄️. C-Set morphisms
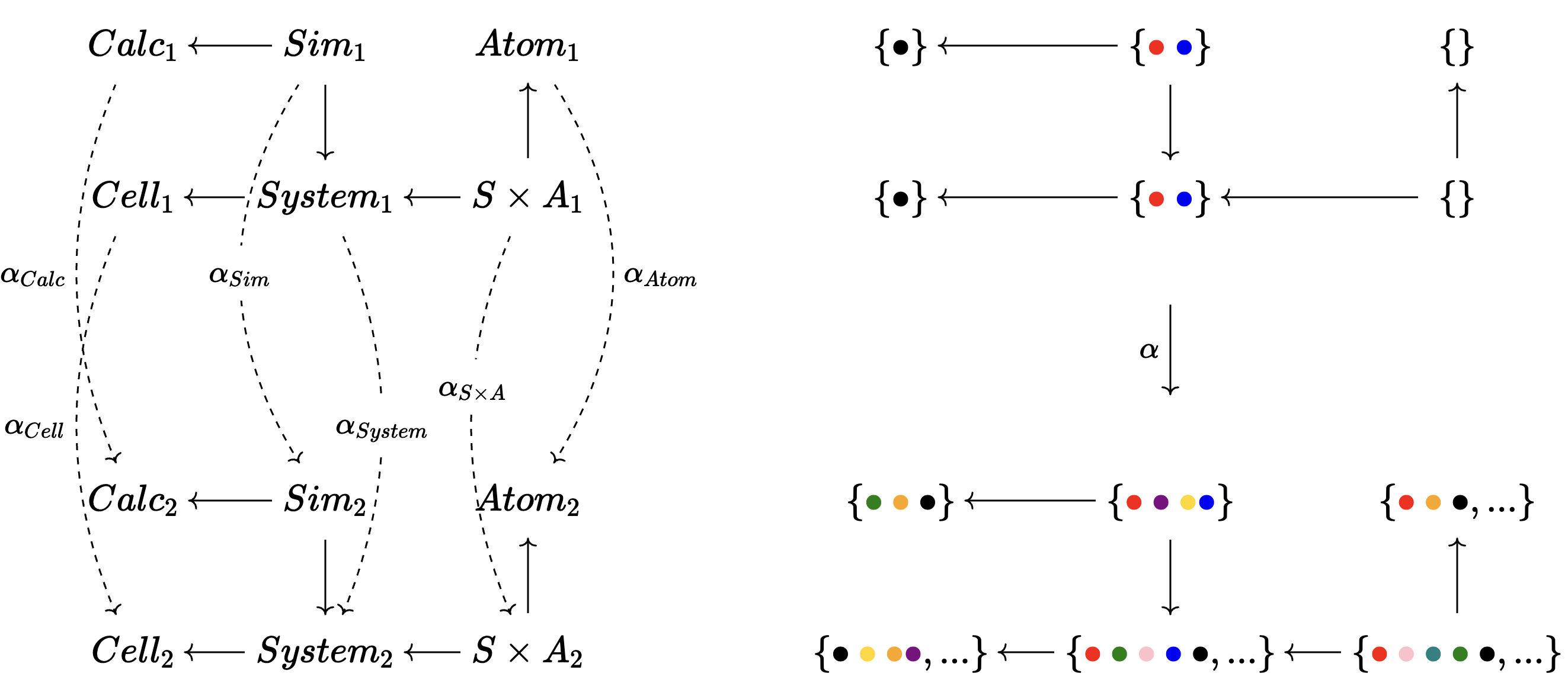
🗄️. Data migration
\[\overset{\Sigma}\Rightarrow\]
\[\longrightarrow\]
\[\underset{\Delta}\Leftarrow\]
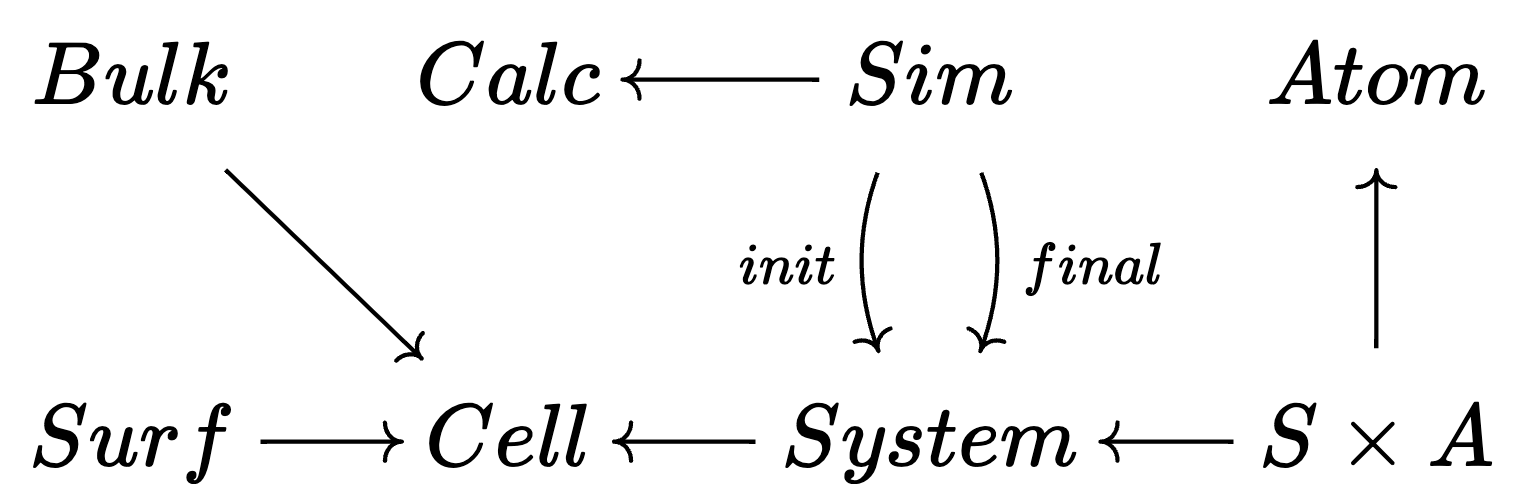
When you design a schema to contain your data, you will soon learn it needs to be updated. This is a huge problem.
Schemas are actually categories; functors between them automatically induce data migrations on arbitrary databases.
When your algorithm is expressed in terms of ACSets, then you can migrate your algorithm automatically, too!
🗄️. Data migration
\[\overset{\Sigma}\Rightarrow\]
\[\longrightarrow\]
\[\underset{\Delta}\Leftarrow\]
# Python
"""System we know nothing about (except pbc)"""
def unknown(pbc):
if pbc == [True,True,True]:
return System(Bulk(0,0,0,pbc), [])
else if pbc == [True, True, False]:
return System(Surf(0,0,0,pbc), [])
"""Migrate a Sim to a Sim2"""
def migrate_sim(sim::Sim):
init_sys = System2(sim.cell, sim.atoms)
final_sys = unknown(init_sys.cell.pbc)
return Sim2(sim.calc, init_sys, final_sys)
for old_sim in get_sims(old_db_cxn):
insert_sim(migrate_sim(old_sim), new_db_cxn)
new_query = "SELECT S1.pth, S2.pth FROM ..."# AlgebraicJulia
"""Declare relationship between schemas"""
F = FinFunctor((system=final,), Simulations, NewSimulations)
"""Constraints"""
Bb, Sb = [true,true,true], [true,true,false]
B = @acset_colim Sims begin b::Bulk; pbc(cell(b))==Bb end
S = @acset_colim Sims begin s::Surf; pbc(cell(b))==Sb end
CB = @acset Sims begin Cell=1; pbc=Bb end
CS = @acset Sims begin Cell=1; pbc=Sb end
constraints = [homomorphism(CB,B), homomorphism(CS,S)]
# Migrate old data
new_simulation_db = Σ(F,constraints)(sims)
# Migrate old query, Q
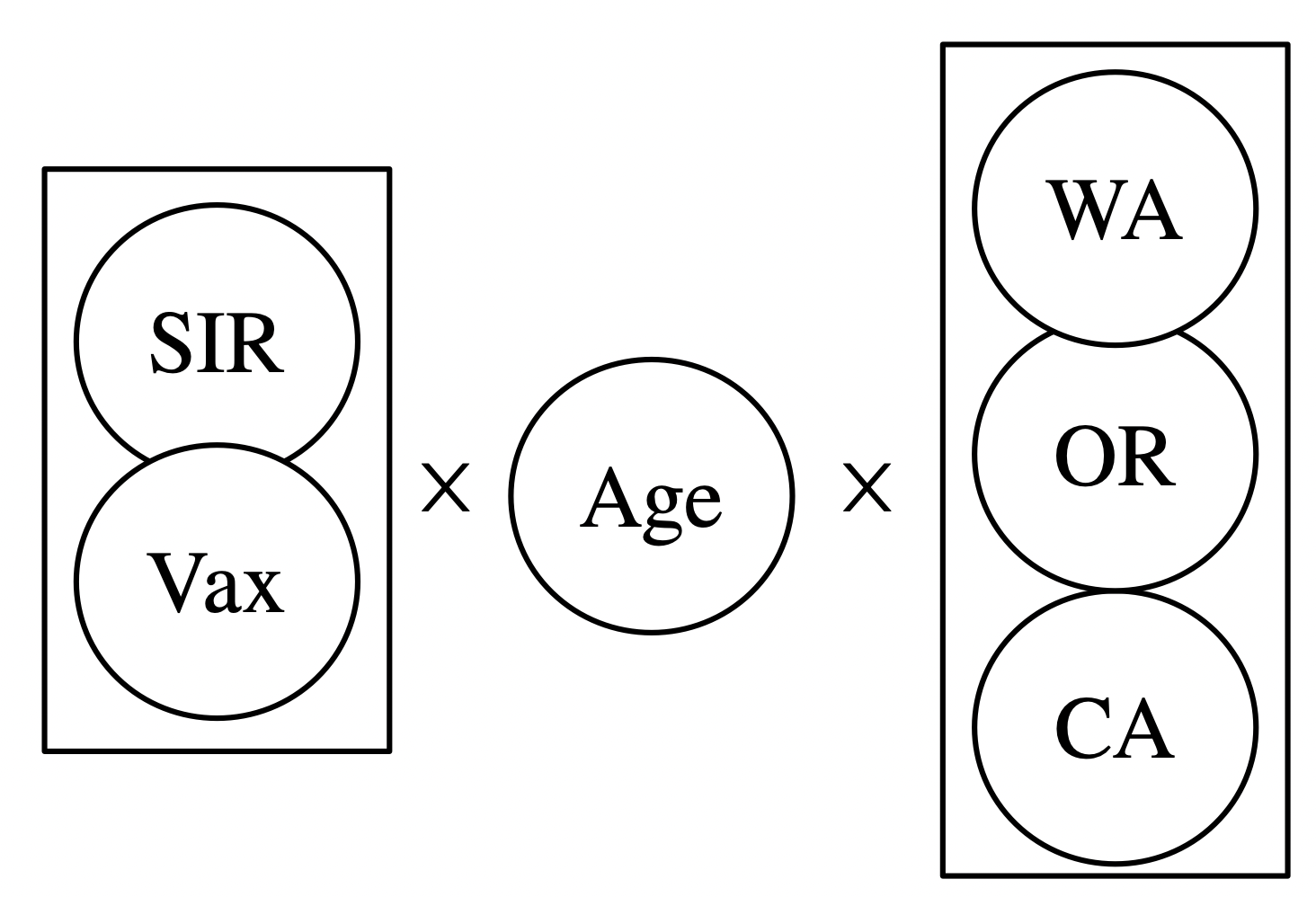
new_Q = Σ(F,constraints)(Q)💭 Models through the eyes of the computer
💭 Models through the eyes of the scientist
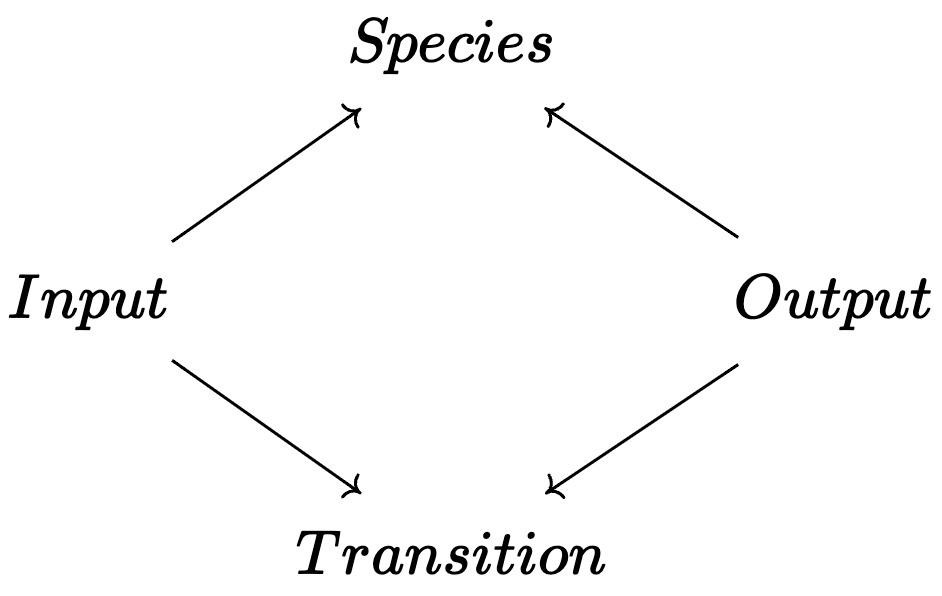
💭 C-Set for Chemical Reaction Networks
The category of Petri nets are just \(\mathsf{C}\)-Sets for a specific \(\mathsf{C}\).
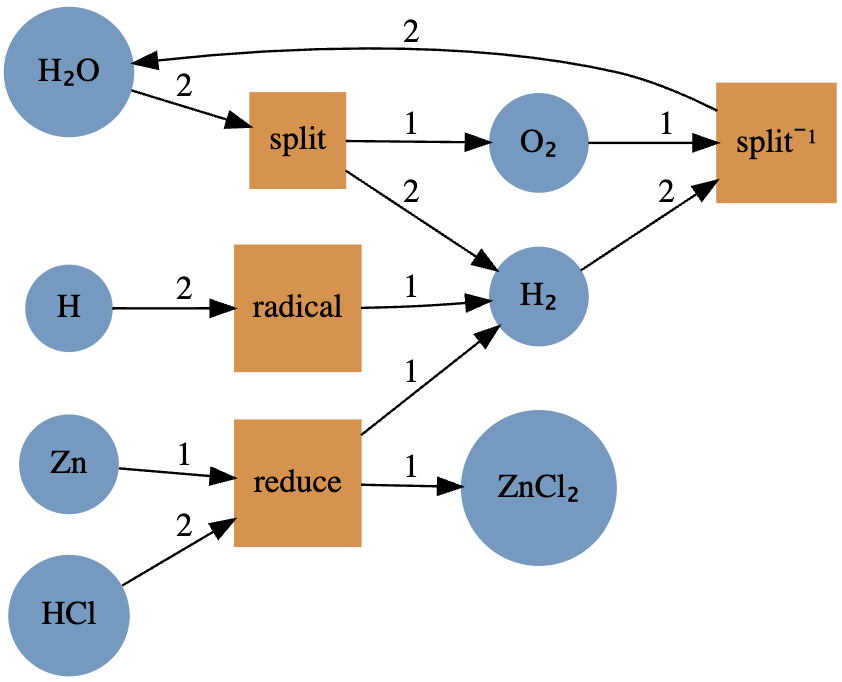
\[2\text{H}_2\text{O}\leftrightarrows 2\text{H}_2+\text{O}_2\]
\[2\text{H}\rightarrow \text{H}_2\]
\[\text{Zn}+2\text{HCl}\rightarrow \text{ZnCl}_2+\text{H}_2\]
using AlgebraicPetri
crn = LabelledPetriNet(
[:H₂O, :H₂, :O₂, :H, :Zn, :ZnCl₂, :HCl],
:split =>((:H₂O, :H₂O)=>(:H₂, :H₂, :O₂)),
:split⁻¹ =>((:H₂, :H₂, :O₂)=>(:H₂O, :H₂O)),
:radical =>((:H,:H)=>:H₂),
:reduce =>((:Zn,:HCl,:HCl)=>(:ZnCl₂,:H₂)),
)
┌───┬─────────┐
│ T │ tname │
├───┼─────────┤
│ 1 │ split │
│ 2 │ split⁻¹ │
│ 3 │ radical │
│ 4 │ reduce │
└───┴─────────┘
┌───┬───────┐
│ S │ sname │
├───┼───────┤
│ 1 │ H₂O │
│ 2 │ H₂ │
│ 3 │ O₂ │
│ 4 │ H │
│...│ ... │
└───┴───────┘
3 rows omitted┌───┬───┬───┐
│ I │it │is │
├───┼───┼───┤
│ 1 │ 1 │ 1 │
│ 2 │ 1 │ 1 │
│ 3 │ 2 │ 2 │
│ 4 │ 2 │ 2 │
│...│...│...│
└───┴───┴───┘
6 rows omitted
┌───┬───┬───┐
│ O │ot │os │
├───┼───┼───┤
│ 1 │ 1 │ 2 │
│ 2 │ 1 │ 2 │
│ 3 │ 1 │ 3 │
│ 4 │ 2 │ 1 │
│...│...│...│
└───┴───┴───┘
4 rows omitted💭 Colimits of CSets: gluing models together
# Python
class Species():
def __init__(self, name: str):
class State():
def __init__(self, species: Dict[Species, Int]):
class Rxn():
def __init__(self, name: str, i: State, o: State):
class RxnNet():
def __init__(self, rxns: List[Rxn]):# AlgebraicJulia
@present LabeledPetriNet(FreeSchema) begin
(S, T, I, O)::Ob
Name::AttrType
is::Hom(I,S); it::Hom(I,T)
os::Hom(O,S); ot::Hom(O,T)
sname::Attr(S,Name)
tname::Attr(T,Name)
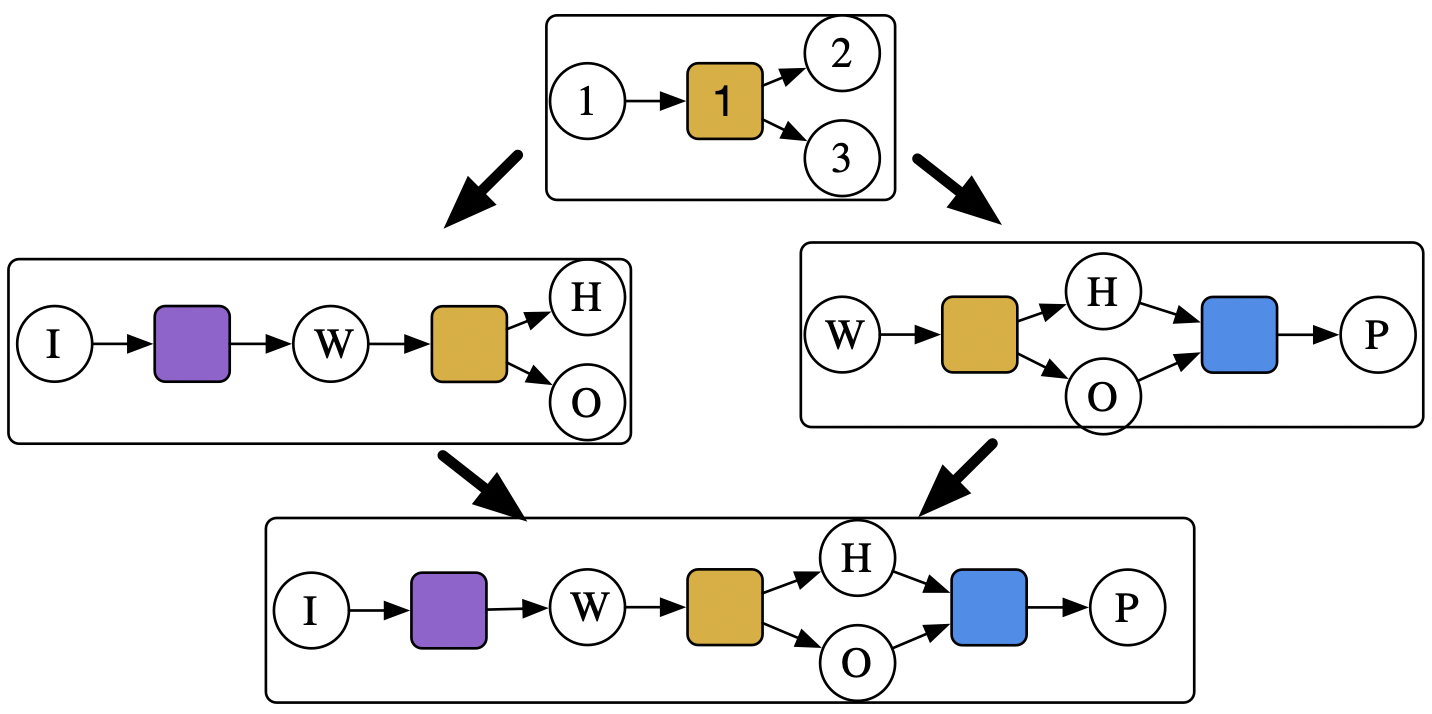
end Write a program that combines overlapping reaction networks:
- e.g. \(\boxed{\text{H}_2\text{O}_s\overset{melt}\rightarrow \text{H}_2\text{O}_l\overset{lyse}\rightarrow \text{H}_2+\text{O}_2}\) and \(\boxed{\text{Water}\overset{zap}\rightarrow \text{H gas}+\text{O gas}\overset{oxidize}\rightarrow Peroxide}\)
- This has one overlapping transition and three overlapping species
# Python
def merge(n1:RxnNet, n2:RxnNet,
s_overlap:list, t_overlap:list):
n1_rxn = deepcopy(n1.rxns)
for r2 in n2.rxns:
n_pairs = [(r1.name,r2.name) for r1 in n1_rxn]
if not intersect(t_overlap, n_pairs):
n1_rxn.append(rename_state(r2, s_overlap))
return RxnNet(n1_rxn)
def rename_state(r::Rxn, s_overlap):
s_dict = dict([(v,k) for (k,v) in s_overlap])
Rxn(r.name, rename_species(r.i, s_dict),
rename_species(r.o, s_dict))
def rename_species(s::Species, s_dict::dict):
Species(get(s_dict,s.name, s.name))# AlgebraicJulia
overlap = @acset PetriNet begin
S=3; T=1; I=1; O=2; it=1; ot=1; is=1; os=[2,3]
end
o_left = homomorphism(overlap, left; monic=true)
o_right = homomorphism(overlap, right; monic=true)
colimit(Span(o_left, o_right)) # standard lib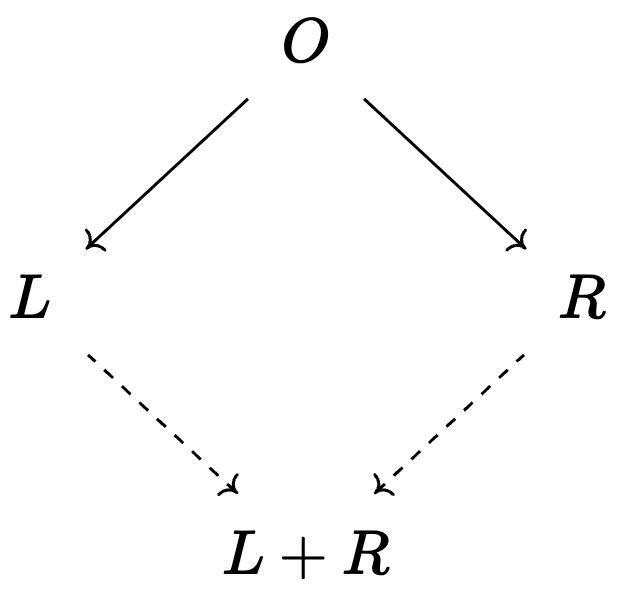
💭 Limits of CSets: model multiplication
Write a program that multiplies all stoichiometry by 2:
# Python
def mul2(r: RxnNet):
RxnNet([Rxn(rxn.name, mul2(rxn.i), mul2(rxn.o))
for rxn in r.rxns])
def mul2(s: State):
State(dict([(k,v*2) for (k,v) in s.species.items()]))# AlgebraicJulia
two = @acset PetriNet begin
I=2; O=2; S=1; T=1;
is=1; it=1; os=1; ot=1
end
mul2(x::PetriNet) = x ⊗ two 
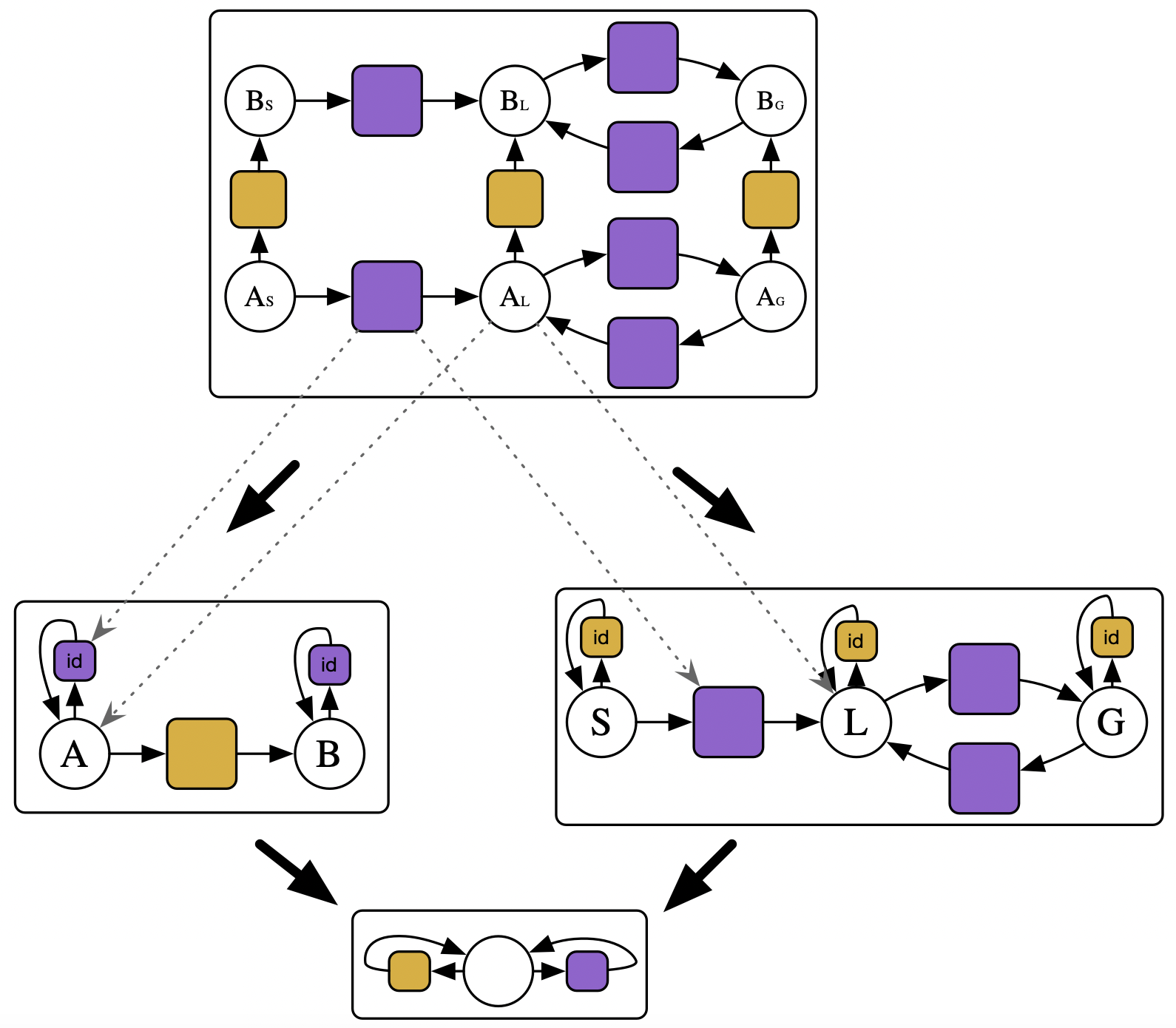
Write a program that stratifies a unary CRN with a CRN of phase transitions:
- e.g. stratifying \(A\rightarrow B\) with \(Solid \rightarrow Liquid \leftrightarrows Gas\) yields:
💭 Limits of CSets: model multiplication
Write a program that stratifies a unary CRN with a CRN of phase transitions:
- e.g. stratifying \(A\rightarrow B\) with \(Solid \rightarrow Liquid \leftrightarrows Gas\)
# Python
def strat(r1: RxnNet, r2:RxnNet):
rs = []
for rx1 in r1.rxns:
for s2 in get_states(r2):
rs.append(rename_rxn(rx1,s2))
for rx2 in r2.rxns:
for s1 in get_states(r1):
rs.append(rename_rxn(rx2,s1))
return RxnNet(rs)
def rename_rxn(r:Rxn, s: Species):
return Rxn(r.name, rSt(r.i,s), rSt(r.o,s))
def rSt(st: State, s2:Species)
return State(Dict([Species(s1.name+s2.name)
for (s1,v) in st.species.items()]))
def get_states(r::RxnNet):
...
📈 Continuous time simulations
Simulations shouldn’t be written as code. The model should be compiled to simulation.
Code is a good semantics category, but lousy for syntax (can’t do fancy things like limits and colimits in it).
# Python
def F(rho, v, MeshCoordi,facenodes,centroid): # advection flux coeff
return -rho*(v @ fnormal(MeshCoordi,facenodes,centroid))
def get_linMatrix(pymesh, custom_mesh, dt, phi0):
. . .
totalMeshCells=len(MeshCells)
fluxMat=numpy.zeros((totalMeshCells, totalMeshCells))
bMat=numpy.zeros((totalMeshCells,1))
for c_cell in range(totalMeshCells):
n_index=0
for n_cell in neighbourID[c_cell]: #n_cell neighbouring cell index
c_ni_faceNodes=cellFaceID[commonFace[c_cell,n_index]]
if n_cell == None: #this will handle the boundary cell elements
fluxMat[c_cell,c_cell], bMat[c_cell]=get_Bcondition(...)
else: #non boundary elements
#D is diffusion flux contribution
D=gamma*gDiff(MeshCoordi,c_ni_faceNodes,[...])
#A is advection flux contribution
A=F(rho,numpy.array([ux,uy]),MeshCoordi,c_ni_faceNodes,[...])
fluxMat[c_cell,n_cell]=-(D*funA(A,D) + max(A,0)) #General scheme by Patankar
n_index+=1
bMat[c_cell]+=rho*cellvolume[c_cell]*phi0[c_cell]/dt
fluxMat[c_cell,c_cell]+= -( numpy.sum(fluxMat[c_cell,:]) - fluxMat[c_cell,c_cell] ) + rho*cellvolume[c_cell]/dt
return fluxMat, bMatConceptual model:
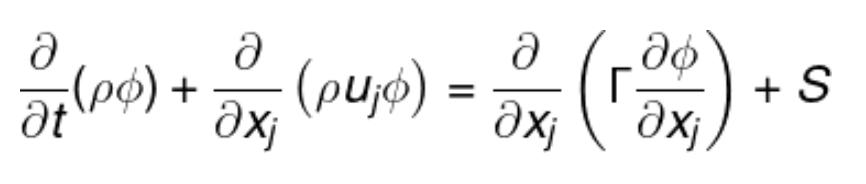
📈 Multiphysics modeling
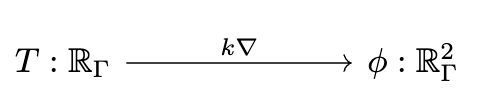
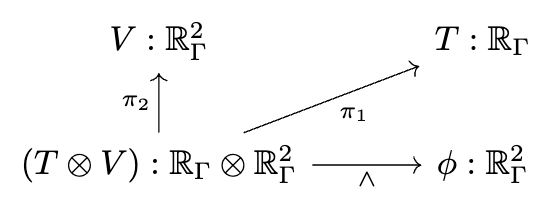
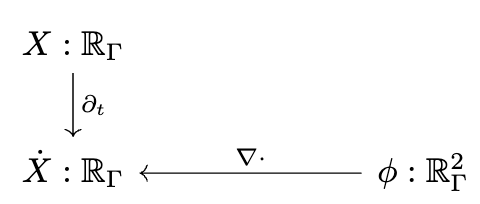
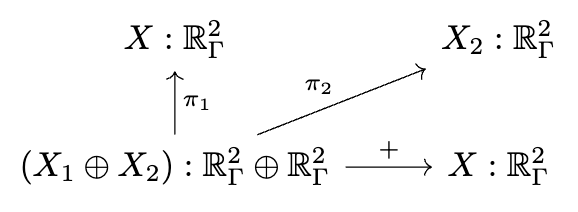
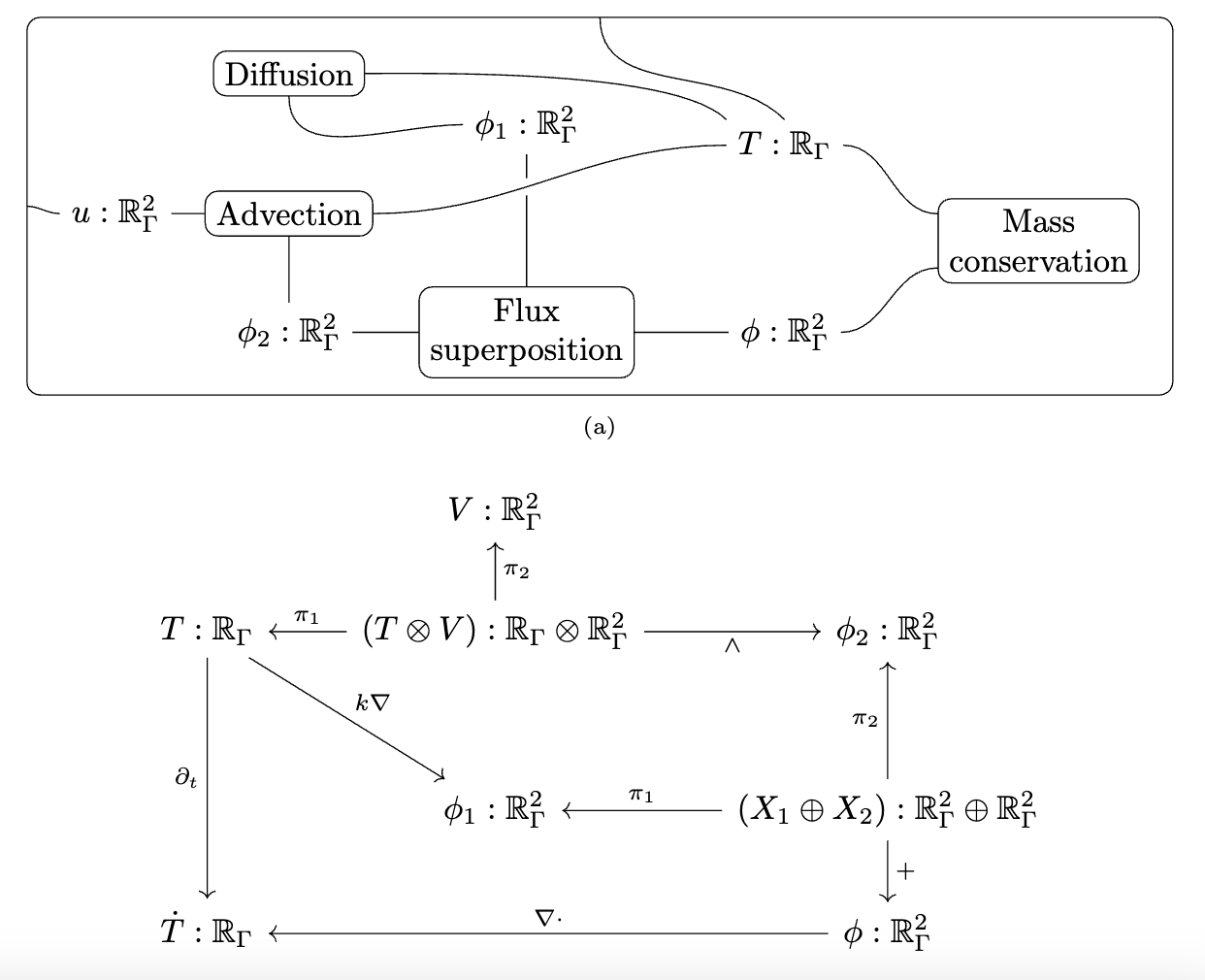
# AlgebraicJulia
"""Define the multiphysics"""
Diffusion = @decapode DiffusionQuantities begin
C::Form0{X}
ϕ::Form1{X}
ϕ == k(d₀{X}(C)) # Fick's first law
end
Advection = @decapode DiffusionQuantities begin
C::Form0{X}
(V, ϕ)::Form1{X}
ϕ == ∧₀₁{X}(C,V)
end
Superposition = @decapode DiffusionQuantities begin
(C, Ċ)::Form0{X}
(ϕ, ϕ₁, ϕ₂)::Form1{X}
ϕ == ϕ₁ + ϕ₂
Ċ == ⋆₀⁻¹{X}(dual_d₁{X}(⋆₁{X}(ϕ)))
∂ₜ{Form0{X}}(C) == Ċ
end
compose_diff_adv = @relation (C, V) begin
diffusion(C, ϕ₁)
advection(C, ϕ₂, V)
superposition(ϕ₁, ϕ₂, ϕ, C)
end"""Geometry"""
mesh = loadmesh(Torus_30x10()) """Assign semantics to operators"""
funcs = sym2func(mesh)
funcs[:k] = Dict(:operator => 0.05 * I(ne(mesh)),
:type => MatrixFunc())
funcs[:⋆₁] = Dict(:operator => ⋆(Val{1}, mesh,
hodge=DiagonalHodge()), :type => MatrixFunc());
funcs[:∧₀₁] = Dict(:operator => (r, c,v)->r .=
∧(Tuple{0,1}, mesh, c, v), :type => InPlaceFunc())📈 Agent based models
# Python
class Wolf():
def init(self, eng: int, position):
def move(self):
...
class Sheep():
def init(self, eng: int, position):
def move(self):
...
class Grass():
def init(self, eng: int, position):
def increment(self):
...
class Graph():
def init(self, vertices, edges):
class World():
def init(self, graph, ws: list[Wolf], ss: list[Sheep]):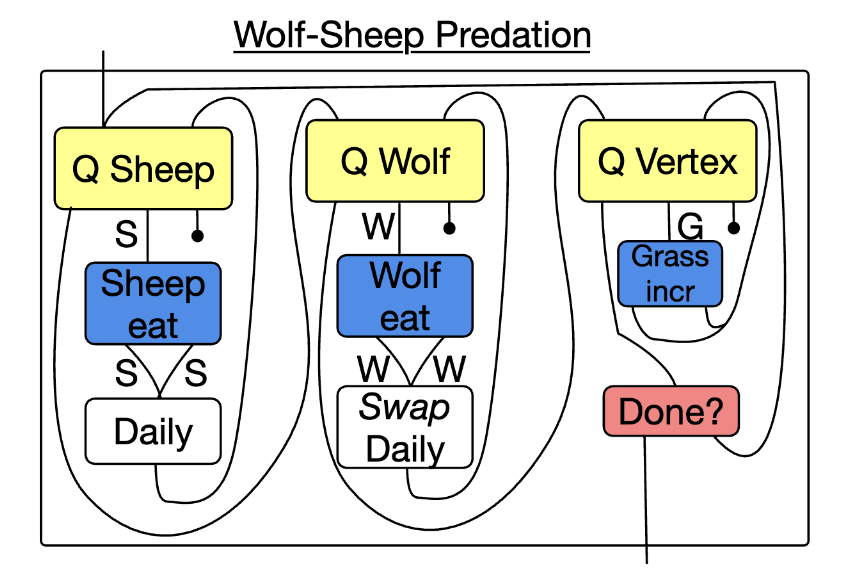

# AlgebraicJulia
Pat = @acset_colim WS begin
s::Sheep; w::Wolf; sheep_loc(s)==wolf_loc(w)
end
Repl = @acset_colim WS begin w::Wolf end
wolf_eat = Rule(homomorphism(Pat, Repl), id(Repl);
expr=(Eng=Dict(1=>vs->vs[3]+vs[2],)))📈 Merging, deleting, copying, adding … without code
Task: find a reaction \(A + B \rightarrow C\), delete \(C\) from the reaction network (if no other reactions need it), merge \(A\) and \(B\) together into \(AB\), and add a reaction \(\varnothing \rightarrow AB\)
# Python
def merge_delete_add(r:RxnNet):
# try to rewrite each reaction
for (i,rxn) in enumerate(r.rxns):
# determine if has at least two inputs
if sum(rxn.i.species.values()) < 2:
continue # cannot rewrite this rxn
# determine if we can delete an output
C = None
for out_species in rxn.o.species.keys():
appears_in = [j for (j, jrxn) in enumerate(r.rxns)
if out_species not in (jrxn.i.species
| jrxn.o.species)]
if appears_in == [i]:
C = out_species
if C is not None: # we can delete an output
out_state = State(Dict([(k,v-1 if k == C else v)
for k,v in rxn.o.species.items()]))
# . . . etc.
# to do: merge two input states
# to do: add a rxn that creates that merged state- What if pattern was changed?
- What if more than one reaction?
- What if reactions merged?
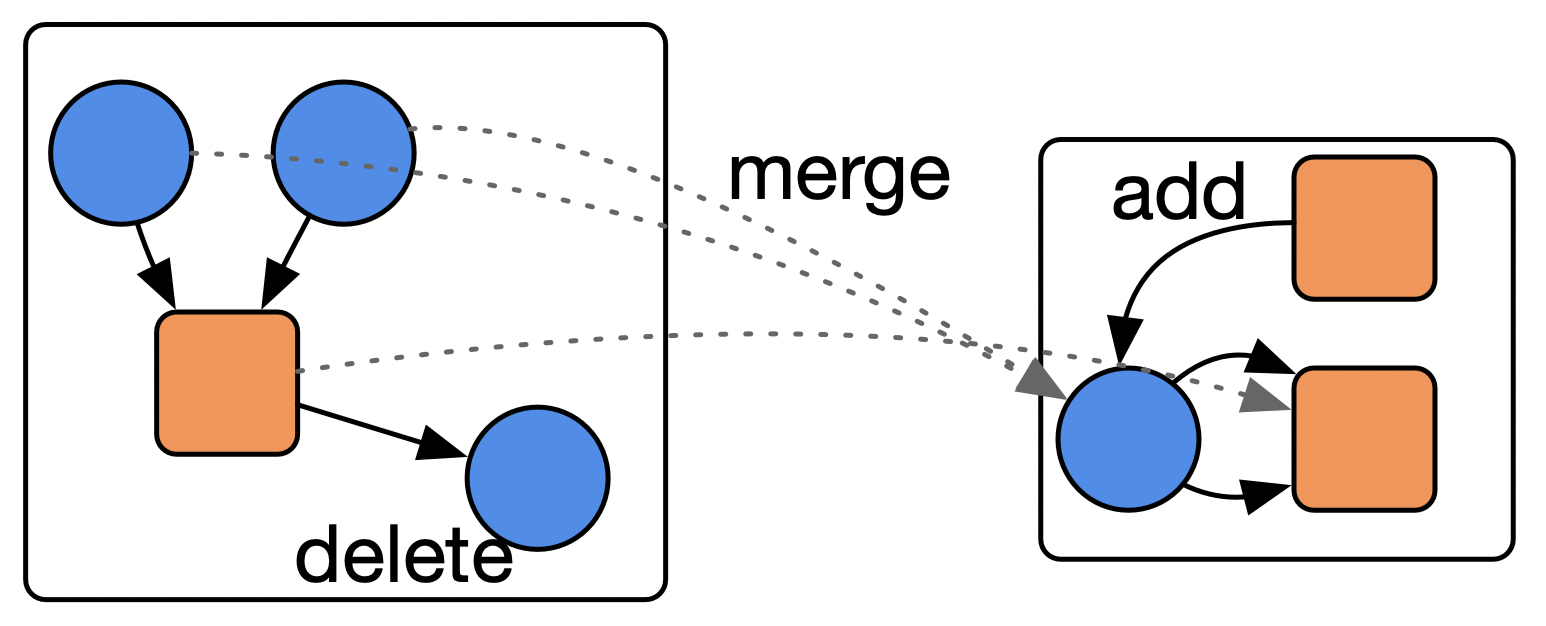
# AlgebraicJulia
Pattern = @acset PetriNet begin
S=3; T=1; I=2; O=1; it=1; ot=1; is=[1,2]; os=[3]
end
# Subobject of Pattern which we do not delete
I = @acset PetriNet begin S=2;T=1;I=2;it=1;is=[1,2];end
Replacement = @acset PetriNet begin
S=1; T=2; I=2; O=1; it=1; ot=2; is=1; os=1
end
rule = Rule(homomorphism(I,Pattern),
homomorphism(I,Replacement))
rewrite(rule, my_rxnet) # uses colimits underneath!Conclusions
Lack of automation due to unclear context and assumptions: models are not explicit.
Formalization creates possibility of automation - important as science scales both in amount of data and conceptual complexity of the data.
💭 Generic model stratification
"""Each S has a distinguished reflexive I, O, T"""
@present SchReflPetriNet <: PetriNet begin
refl_i::Hom(S,I)
refl_o::Hom(S,O)
refl_i ⋅ is == id
refl_o ⋅ os == id
refl_i ⋅ it == refl_o ⋅ ot
end
F = FinFunctor(SchPetriNet, SchReflPetriNet)base = @acset PetriNet begin
S=1; T=2; I=2; O=2;
is=1; os=1; it=[1,2]; ot=[1,2]
end
"""
Apply Σ;Δ migration to input X, then map into base
X transitions are sent to 1, added refl transitions to 2
(vice-versa if t = false)
"""
function strat_arr(X::PetriNet, t::Bool)
to_refl = ΣΔ(F)(X) # yields a morphism X → X′
Refl = codom(X_X′) # X, with reflective transitions
L = collect(to_refl[:T]) # set of original T's in X
# Determine where to send transitions in base
t_init = [p ∈ L ? t : !t for p in parts(Refl,:T)] .+ 1
homomorphism(Refl, base; initial=(T=t_init,))
end
function stratify(X::PetriNet, Y::PetriNet)
csp = Cospan(strat_arr(X, true), strat_arr(Y, false))
return Limit(csp)
end 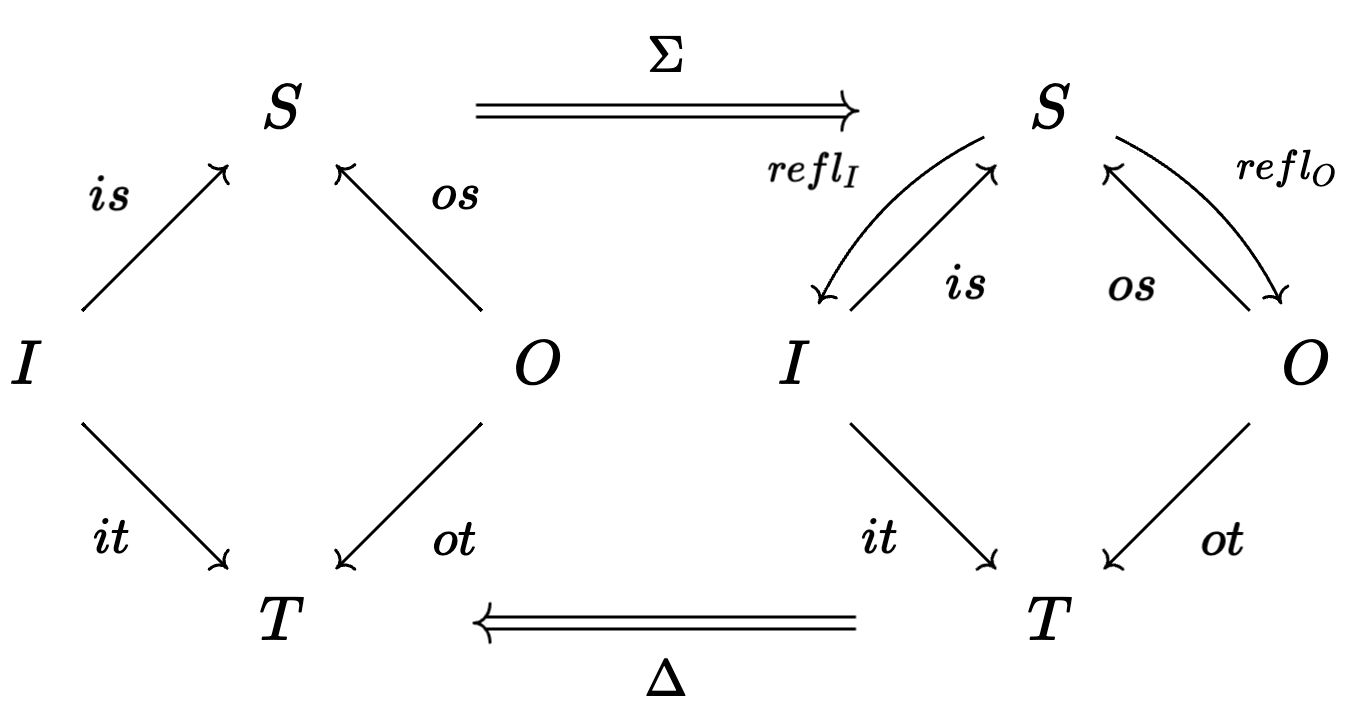
Graph morphism
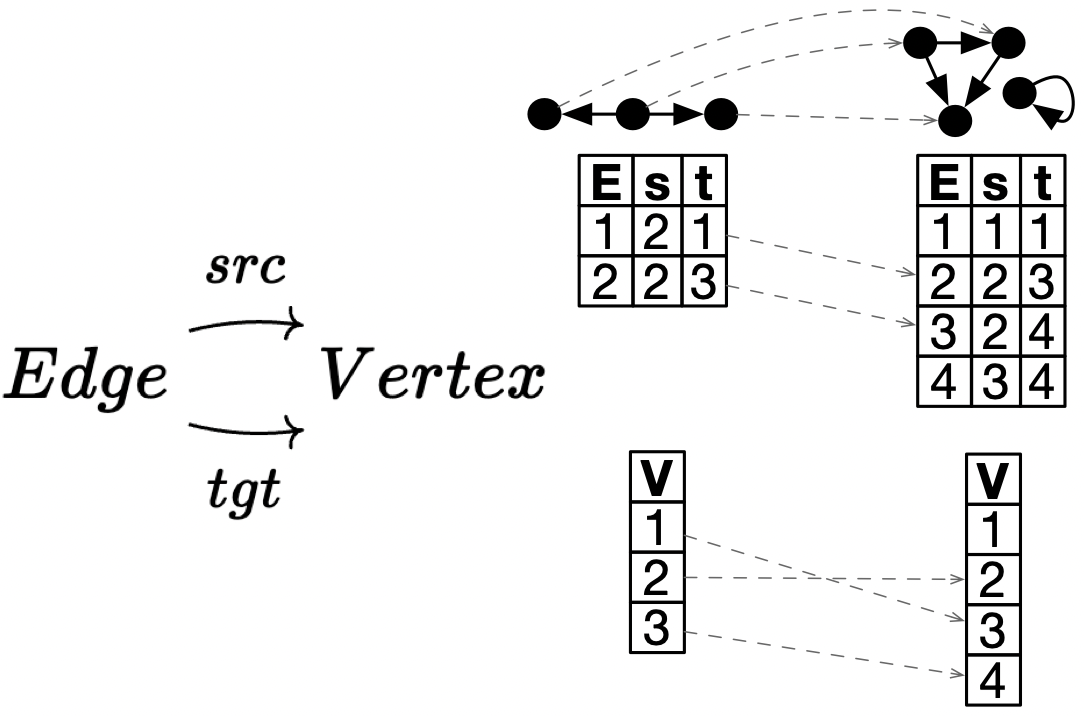
Q = @colim_repr Graph begin
(e1, e2)::Edge
src(e1) == src(e2)
end
homomorphisms(Q, my_graph)